- LSTM

LSTM
主要内容
概述
 LSTM(4)LSTM是一种含有LSTM区块(blocks)或其他的一种类神经网络,文献或其他资料中LSTM区块可能被描述成智能网络单元,因为它可以记忆不定时间长度的数值,区块中有一个gate能够决定input是否重要到能被记住及能不能被输出output。
LSTM(4)LSTM是一种含有LSTM区块(blocks)或其他的一种类神经网络,文献或其他资料中LSTM区块可能被描述成智能网络单元,因为它可以记忆不定时间长度的数值,区块中有一个gate能够决定input是否重要到能被记住及能不能被输出output。
LSTM有很多个版本,其中一个重要的版本是GRU(Gated Recurrent Unit),根据谷歌的测试表明,LSTM中最重要的是Forget gate,其次是Input gate,最次是Output gate。
结构
LSTM内部主要有三个阶段:
1. 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
2. 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。
3. 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。
训练
为了最小化训练误差,梯度下降法(Gradient descent)如:应用时序性倒传递算法,可用来依据错误修改每次的权重。梯度下降法在递回神经网络(RNN)中主要的问题初次在1991年发现,就是误差梯度随着事件间的时间长度成指数般的消失。当设置了LSTM 区块时,误差也随着倒回计算,从output影响回input阶段的每一个gate,直到这个数值被过滤掉。因此正常的倒传递类神经是一个有效训练LSTM区块记住长时间数值的方法。
对比
RUN
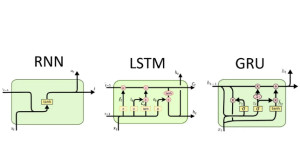
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
 LSTM结构与RUN结构对比图
LSTM结构与RUN结构对比图
LSTM的内部结构。通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
HMM
LSTM的表现通常比时间递归神经网络及隐马尔科夫模型(HMM)更好,比如用在不分段连续手写识别上。
应用领域
在 2015 年,谷歌通过基于CTC 训练的 LSTM 程序大幅提升了安卓手机和其他设备中语音识别的能力,其中就使用了Jürgen Schmidhuber的实验室在 2006 年发表的方法。百度也使用了 CTC;苹果的 iPhone 在 QuickType 和Siri中使用了 LSTM;微软不仅将 LSTM 用于语音识别,还将这一技术用于虚拟对话形象生成和编写程序代码等等。亚马逊 Alexa 通过双向 LSTM 在家中与你交流,而谷歌使用 LSTM 的范围更加广泛,它可以生成图像字幕,自动回复电子邮件,它包含在新的智能助手 Allo 中,也显著地提高了谷歌翻译的质量(从 2016 年开始)。目前,谷歌数据中心的很大一部分计算资源现在都在执行 LSTM 任务。
工作原理
LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。
一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。
说起来无非就是一进二出的工作原理,却可以在反复运算下解决神经网络中长期存在的大问题。目前已经证明,LSTM是解决长序依赖问题的有效技术,并且这种技术的普适性非常高,导致带来的可能性变化非常多。各研究者根据LSTM纷纷提出了自己的变量版本,这就让LSTM可以处理千变万化的垂直问题。[1]
 LSTM的内部处理器和三重门
LSTM的内部处理器和三重门


-

Plus上市 别克昂科威S及昂科威S艾维亚将于7月29日上市
2025-10-04 01:31:08 查看详情 -
全新紧凑型SUV/上半年上市 别克昂科拉PLUS最新谍照
2025-10-04 01:31:08 查看详情 -
黄海纯电轿车Smile将于12月上市 29万元
2025-10-04 01:31:08 查看详情 -
江铃宝典堪称商用皮卡常青树 江铃新宝典VS长城风骏7(图文)
2025-10-04 01:31:08 查看详情 -
380TSI劲擎智联版四驱车型上市 成都车展:雪铁龙C
2025-10-04 01:31:08 查看详情 -
Air正式上市 长安福特锐际将新增ST
2025-10-04 01:31:08 查看详情 -
家族纯电SUV旗舰/2024年国产上市 23万元起/月底上市
2025-10-04 01:31:08 查看详情 -
55周年纪念版上市 上汽MAXUS
2025-10-04 01:31:08 查看详情 -
将于2月28日正式上市 定位纯电旗舰SUV
2025-10-04 01:31:08 查看详情 -
改款丰田威尔法4月30日上市 吉利豪越中型SUV有望6月上市
2025-10-04 01:31:08 查看详情

 求购
求购