- 稀疏编码

稀疏编码
起源
人眼视觉感知机理的研究表明,人眼视觉系统(Human Visual System, HVS)可看成是一种合理而高效的图像处理系统.在人眼视觉系统中,从视网膜到大脑皮层存在一系列细胞,以“感受野”模式描述.感受野是视觉系统信息处理的基本结构和功能单元,是视网膜上可引起或调制视觉细胞响应的区域.它们被视网膜上相应区域的光感受细胞所激活,对时空信息进行处理.神经生理研究已表明:在初级视觉皮层(Primary Visual Cortex)下细胞的感受野具有显著的方向敏感性,单个神经元仅对处于其感受野中的刺激做出反应,即单个神经元仅对某一频段的信息呈现较强的反映,如特定方向的边缘、线段、条纹等图像特征,其空间感受野被描述为具有局部性、方向性和带通特性的信号编码滤波器.而每个神经元对这些刺激的表达则采用了稀疏编码(Sparse Coding, SC)原则,将图像在边缘、端点、条纹等方面的特性以稀疏编码的形式进行描述.从数学的角度来说,稀疏编码是一种多维数据描述方法,数据经稀疏编码后仅有少数分量同时处于明显激活状态,这大致等价于编码后的分量呈现超高斯分布.在实际应用中,稀疏编码有如下几个优点:编码方案存储能力大,具有联想记忆能力,并且计算简便;使自然信号的结构更加清晰;编码方案既符合生物进化普遍的能量最小经济策略,又满足电生理实验的结论。
研究历史
1959年,David Hubel和Toresten Wiesel通过对猫的视觉条纹皮层简单细胞感受野的研究得出一个结论:主视皮层V1区神经元的感受野能对视觉感知信息产生一种“稀疏表示”。
1961年,H.B.Barlow基于这一知识提出了“利用感知数据的冗余”进行编码的理论。
1969年,D.J.Willshaw和O.P.Buneman等人提出了基于Hebbian 学习的局部学习规则的稀疏表示模型.这种稀疏表示可以使模型之间有更少的冲突,从而使记忆能力最大化.Willshaw模型的提出表明了稀疏表示非常有利于学习神经网络中的联想。
1972年,Barlow推论出在稀疏性(Sparsity)和自然环境的统计特性之间必然存在某种联系.随后,有许多计算方法被提出来论证这个推论,这些方法都成功地表明了稀疏表示可以体现出在大脑中出现的自然环境的统计特性。
1987年,Field提出主视皮层V1区简单细胞的感受野非常适于学习视网膜成像的图像结构,因为它们可以产生图像的稀疏表示.基于这个结论,1988年,Michison明确提出了神经稀疏编码的概念,然后由牛津大学的E.T.Roll 等人正式引用.随后对灵长目动物视觉皮层和猫视觉皮层的电生理的实验报告,也进一步证实了视觉皮层复杂刺激的表达是采用稀疏编码原则的。
1989年,Field提出了稀疏分布式编码(Sparse Distributed Coding)方法.这种编码方法并不减少输入数据的维数,而是使响应于任一特殊输入信息的神经细胞数目被减少,信号的稀疏编码存在于细胞响应分布的四阶矩(即峭度Kurtosis)中。
1996年,Olshausen和Field在Nature杂志上发表了一篇重要论文指出,自然图像经过稀疏编码后得到的基函数类似于V1区简单细胞感受野的反应特性.这种稀疏编码模型提取的基函数首次成功地模拟了V1区简单细胞感受野的三个响应特性:空间域的局部性、时域和频域的方向性和选择性.考虑到基函数的超完备性(基函数维数大于输出神经元的个数),Olshausen 和Field在1997年又提出了一种超完备基的稀疏编码算法,利用基函数和系数的概率密度模型成功地建模了V1区简单细胞感受野。
1997年,Bell和Sejnowski 等人把多维独立分量分析(Independent Component Analysis, ICA)用于自然图像数据分析,并且得出一个重要结论:ICA实际上就是一种特殊的稀疏编码方法。
21世纪以来,国外从事稀疏编码研究的人员又提出了许多新的稀疏编码算法,涌现出了大量的稀疏编码方面的论文,国内研究者在稀疏编码算法和应用方面也作了一些工作],但远远落后于国外研究者所取得的成果。
原理
假设有一组基向量![]() ,将输入向量
,将输入向量![]() 表示为这些基向量的线性组合:
表示为这些基向量的线性组合:
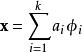
虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组'''“超完备”'''基向量来表示输入向量![]() (也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数
(也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数![]() 不再由输入向量
不再由输入向量![]() 单独确定。因此,在稀疏编码算法中,我们另加了一个评判标准'''“稀疏性”'''来解决因超完备而导致的退化(degeneracy)问题。
单独确定。因此,在稀疏编码算法中,我们另加了一个评判标准'''“稀疏性”'''来解决因超完备而导致的退化(degeneracy)问题。
这里,我们把“稀疏性”定义为:只有很少的几个非零元素或只有很少的几个远大于零的元素。要求系数![]() 是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。同时,比如与初级视觉皮层的类比过程也因此得到了提升。
是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。同时,比如与初级视觉皮层的类比过程也因此得到了提升。
我们把有m个输入向量的稀疏编码代价函数定义为:
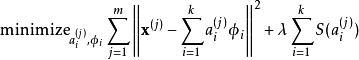
此处![]() 是一个稀疏代价函数,由它来对远大于零的
是一个稀疏代价函数,由它来对远大于零的![]() 进行“惩罚”。我们可以把稀疏编码目标函式的第一项解释为一个重构项,这一项迫使稀疏编码算法能为输入向量
进行“惩罚”。我们可以把稀疏编码目标函式的第一项解释为一个重构项,这一项迫使稀疏编码算法能为输入向量![]() 提供一个高拟合度的线性表达式,而公式第二项即“稀疏惩罚”项,它使
提供一个高拟合度的线性表达式,而公式第二项即“稀疏惩罚”项,它使![]() 的表达式变得“稀疏”。常量
的表达式变得“稀疏”。常量![]() 是一个变换量,由它来控制这两项式子的相对重要性。
是一个变换量,由它来控制这两项式子的相对重要性。
虽然“稀疏性”的最直接测度标准是 "![]() " 范式(
" 范式(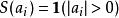 ),但这是不可微的,而且通常很难进行优化。在实际中,稀疏代价函数
),但这是不可微的,而且通常很难进行优化。在实际中,稀疏代价函数![]() 的普遍选择是
的普遍选择是![]() 范式代价函数
范式代价函数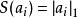 及对数代价函数
及对数代价函数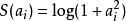 。
。
此外,很有可能因为减小![]() 或增加
或增加![]() 至很大的常量,使得稀疏惩罚变得非常小。为防止此类事件发生,我们将限制
至很大的常量,使得稀疏惩罚变得非常小。为防止此类事件发生,我们将限制![]() 要小于某常量C。包含了限制条件的稀疏编码代价函数的完整形式如下:
要小于某常量C。包含了限制条件的稀疏编码代价函数的完整形式如下:
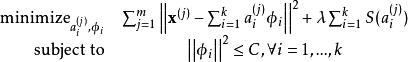
稀疏编码的应用
近年来,许多神经生理学家在视觉系统上已展开了全面深入的研究,并且取得了一些有重要意义的研究成果.这就使得在工程上利用计算机来模拟视觉系统成为可能.基于这一认识,利用已有的生物学科研成果,联系信号处理、计算理论以及信息论知识,通过对视觉系统进行计算机建模,使计算机能在一定程度上模拟人的视觉系统,以解决人工智能在图像处理领域中碰到的难题.神经稀疏编码算法正是这样一种建模视觉系统的人工神经网络方法。这种算法编码方式的实现仅依靠自然环境的统计特性,并不依赖于输入数据的性质,因而是一种自适应的图像统计方法。
稀疏编码SC方法在盲源信号分离、语音信号处理、自然图像特征提取、自然图像去噪以及模式识别等方面已经取得许多研究成果,具有重要的实用价值,是当前学术界的一个研究热点.进一步研究稀疏编码技术,不仅会积极地促进图像信号处理、神经网络等技术的研究,而且也将会对相关领域新技术的发展起到一定的促进作用。


-

奥迪电动车胎压如何编码(奥迪电动车胎压怎么编码)
2025-10-05 03:25:34 查看详情 -

-

-
-
-
新款大切诺基后汽包编码是多少
2025-10-05 03:25:34 查看详情 -

-

-

-

 求购
求购